

As the world accelerates towards net-zero, investors are needing to quantify portfolio-level carbon risk from the bottom-up across their equities. But there are still big problems in sourcing high quality, timely carbon data that covers enough of the global market. But don’t worry - there is a way forward for investors.
In this newsletter I describe some of the data challenges that exist and the approach we have taken at Emmi to help you navigate the net-zero world of finance.
Big carbon data challenges exist
Old data
To make the best decisions, investors need the latest data. For carbon however, the data is almost always more than 12-18 months old, which makes it less useful to drive decision-making. Since the latest carbon data is tied to when a company voluntarily discloses, it can sometimes be an after-thought and it’s not uncommon for data to be even two years old.
Information must be timely for any market to function efficiently- and current carbon data fails to provide this to all market participants.
Lack of Coverage
The majority of global equities have never reported on carbon emissions - EVER - creating another big gap in the carbon information market. The lack of reporting is particularly evident for small to mid-sized companies and in the developing world. Coverage is a major challenge for investors, with most portfolios needing wider and more granular data outside the large companies and indices.
The Scope 3 problem
Carbon emission reporting for companies is guided by the GHG Protocol which divides greenhouse gas emissions into three scopes.
- Scope 1 emissions which come directly from a company and its controlled entities.
- Scope 2 emissions come from the generation of purchased energy.
- Scope 3 emissions are all indirect (value chain) emissions - like how customers use the product.
Annual carbon emission disclosure and reporting is slowly getting better via initiatives such as the Carbon Disclosure Project, but is still voluntary. Each year, the number of companies who voluntarily disclose grows and currently sits at ~7,000 globally.
However it’s important to understand that Scope 3 is often mis-reported or unreported and that can make a big difference.
For Scope 3, there are 15 different categories to report under the GHG Protocol. Employee and business travel tends to be well reported, but quantifying emissions from ‘Use of Sold Products’ is more difficult to calculate so often goes unreported.
For example, Chevron recently came under fire for only reporting Scope 1 & 2 in setting their net-zero targets. The company did not report Scope 3 emissions which are generally >10x higher in oil & gas.
Only a fraction of companies disclose Scope 3 emissions and of those that do, many are selective about the categories they report on. Given its importance, how can investors get better insights into carbon risk and temperature alignment without it?
Trust and Uncertainty
Some companies put resources towards quantifying their carbon emissions data. Some even get third-party carbon auditors to verify their annual emissions. But most companies don’t have resources or do the minimum. This creates a quality and trust problem across the market. How much can we trust the reported data?
Black-box models
To overcome some of the problems listed above, carbon data vendors often predict emissions for Scope 3 as an example - but often the methods are secretive and opaque. It’s extremely difficult to trust any model that lacks transparency.
Blackrock recently disclosed its carbon footprint for its entire global portfolio. The world’s largest fund manager could only estimate its carbon emissions for 65% of its portfolio. The other 35% lacked the data quality and/or methodology to quantify it. This highlights the overall challenges existing today due to sub-optimal carbon data and or models.
A different approach
For us at Emmi, carbon data is a the first critical element to building the financial infrastructure and tools required for the net-zero world. So I thought it would be helpful to others to learn our approach to overcome some of those data problems.
1. Better Research to Predict Carbon
To solve some of the carbon data challenges, we need to discover new ways of predicting carbon emissions. So a couple of years ago I went on a mission to find innovative teams in academia and found a novel piece of research that used a machine learning approach to predict corporate carbon emissions. It was written by Dr Quyen Nguyen and Associate Professor Ivan Diaz-Rainey at the Climate and Energy Finance Group (CEFGroup) at the University of Otago.
We reached out immediately and have been fortunate to collaborate to expand their techniques allowing better predictive models that help us solve some of the carbon data challenges.

2. Aggregate, expand and compare carbon data
For company carbon emission data, it’s best to break it up into three segments which depend on what data is available at the company level.
Reported data are carbon emissions provided voluntarily by the company via external data providers like CDP and others.
Estimated data are emissions where the company has historically reported carbon emissions in two or more years, but with gaps in recent years or over time. We then use models to estimate the latest year of data or fill gaps in older data.
Predicted data are emissions where the company has never reported carbon emissions. In this case we use predictive models based purely on financial data.
2.1 Reported Carbon Data
Instead of relying on one data vendor, our approach is to aggregate carbon data from three different providers for comparison: Bloomberg, Refinitiv and ISS. Each have different methodologies and coverage of carbon data and they do rely somewhat on republishing emissions from the Carbon Disclosure Project (CDP), which have the largest dataset of reported emissions: currently ~7,000 companies.
But that is not wide enough to cover the +40k companies across global public markets. How can we expand the coverage to make it useful for portfolio managers? We have developed a 5 step process that encompasses our approach to building better carbon data for investors.

2.2 Estimated Carbon Data
Estimated data are emissions where the company has historically reported carbon emissions in two or more years, but there are gaps in recent years or over time. We then use regression models to estimate the latest year of data or fill gaps in older data.
The first regression model uses either Revenue & Employees or Revenue or Employees dependent on data availability along with historical emissions. The data is split into training, testing and validation and uses categorical predictors for each GICS sector. It is used for gap filling across companies within a GICS sub-sector within a single year.
The second method we use is for a single company which has reported historically two or more times. Our research with the University of Otago, has found that estimating carbon emissions for companies that have reported more than twice provides the most robust estimates of any method we have researched.
Overall, estimating carbon emissions has a much higher confidence than predicting emissions when companies have never reported.

2.3 Predicted Carbon Data
Predicted data are emissions where the company has never reported carbon emissions previously. In this case we use predictive models based purely on financial data and GICS sector information.
For our initial data release in September 2021, we used an industry fill method. Our next data release in 2022 will include our machine learning predictive models that we have developed with the University of Otago. This research will be published in an academic journal.
The industry fill method takes a bottom up approach to predicting carbon emissions for companies that have never reported. We cluster reported carbon into sub-industries, GICS and sectors to find their closest peers. We then calculate the Scope/Revenue Ratio of their peers. Using company financial data we then multiply this ratio to predict emissions.
The accuracy and confidence of this approach is low, but varies widely depending on the sector. Some sub-industries have tightly defined distribution of data, while others (like materials which have diverse business activities) have a wide distribution of carbon data. There are limitations especially on small firms in industries dominated by large producers, as this method assumes that all companies within their respective sector are as Revenue : Emissions efficient as one another.
Given the various sources of reported data and the models we use to estimate and predict emissions, it is important to be open and transparent about Emmi’s methodology, while also providing a data-centric approach to gauge the trustworthiness of the carbon data across the +42k equities we have assessed.
3. Build a Carbon Trust Framework
Why is carbon trust important?
Whether reported or estimated, corporate carbon emissions are inherently uncertain, particularly for Scope 3. Despite this, companies and data providers cant easily disclose the uncertainty of this reported data. Is it +/-10%, +/-50% or +/-100%?
To build a global standard on assessing carbon risk, it is essential we can quantify the trustworthiness and uncertainty of corporate emissions. At Emmi we assess the accuracy of reported and our modeled emissions by combining statistical outlier analysis with a range of clustering and/or temporal volatility analysis. Without a single source of truth from corporate carbon, the premise of our approach revolves around comparing independent sources for data, both reported and modeled.
How does Emmi Calculate Carbon Trust?
Each company can have multiple sources of carbon data and estimates using our models. We combine this ensemble to understand the trustworthiness of the data we use to assess carbon risk.
We assign trust by asking ourselves:
- Do different data providers report similar emissions?
- Does the reported value appear to be under-reported compared to its industry peers or the ensemble of Emmi modeled estimates?
- What is the range of the Emmi emission estimate ensemble?
- Are estimates relatively consistent between years?
After a number of checks, we assign a level of trust to a company as a whole, their scope 1&2 and also their scope 3 emissions data. Company emissions are ranked with a trust score between A and D, where A has high confidence in the reported data, and D should be taken as very uncertain.
Using our method, we generate Scope 1,2 and 3 emission predictions and trust scores for over 40,000 publicly listed securities. See below a histogram of our trust scores within the Emmi carbon data universe.

Our process is generally conservative when it comes to the high level rankings, with around 12,000 companies receiving an A or B. The lowest trust companies ranked D is larger (~18,000), however this is due to the volume of companies that misreport or don’t report emissions. Scope 3 is generally penalised due to it’s difficulty in reporting and predicting.
4. Embrace the Uncertainty Using Data!
Corporate carbon data is always going to be uncertain, particularly when predicting across tens of thousands of companies. However what is most important to investors is whether that uncertainty materially impacts the carbon financial exposure of a company and portfolio. Traditionally, it has been difficult for investors to know whether their portfolio is exposed even if the data is uncertain.
But by integrating finance with carbon within a data science framework, we can for the first time propagate carbon data uncertainties that allow investors a data-driven perspective on whether a company or portfolio is truly a carbon risk.
Below is the example output from 6 companies, where we build Monte-Carlo simulations to understand if carbon risk materially changes because of carbon data uncertainty (high risk =0, low risk =100). All the dots are independent simulations - and you can see that for most companies, the uncertainty in carbon data doesn’t change the overall risk band (Box range).
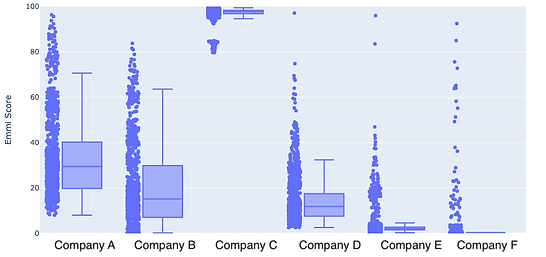
So instead of not knowing the uncertainty of carbon data and hiding from it like in the past - it’s of critical importance for us at Emmi, since it provides a complete picture of the carbon risk exposure, giving our clients more certainty in their decisions.
Carbon data will always be challenging and there will always be uncertainty. But fortunately for investors, these challenges are manageable if using predictive models with known uncertainties that can then be integrated into financial risk for their portfolios. This will give investors a more certain understanding of carbon transition risk so they can make the best investment decisions in deploying their capital.
If you are stuck on access to carbon data and portfolio-level carbon risk for your own universe of companies and want any help - just reply to this message to email me.. I’m keen to help.
Stay safe and well,
Ben


